고정 헤더 영역
상세 컨텐츠
본문
728x90
문장은 어떻게 처리해야할까? -> 여러 토큰이 연결된 모양인 sequence로 해석하면?? => RNN!
- Word Embedding (BOW, TF-IDF, Word2Vec)
- Markov chain
- teacher forcing
- BPTT
- GRU
- LSTM
문장을 처리하고 싶으면, 우선 '단어'를 어떻게 벡터로 표현할것인가부터 정해야 한다. => word embedding
문장은 길이가 다양하다는 단점이 있었다 (특정 크기의 matrix에 끼워넣기가 힘듦) -> TF-IDF 로 해결 (n개의 document, v개의 vocab, 을 묶어서 v*n 행렬로 묶은것!)
뿐만 아니라 단어를 oine-hot encoding으로 처리하면, 모든 단어들의 거리가 같다는 문제가 있음 (단어간의 유사도파악이 힘들다) -> Word embedding으로 해결! (단어벡터의 차원을 고정시켜둔것!)
[TF-IDF]
- BOW : bag of words : 하나의 document에 몇개의 단어가 있는지
- TF : 특정 document에, 특정 단어가 몇번 등장하는지
- DF : 특정 단어가 몇개의 document에 등장하는지
- IDF : DF의 inverse
- TFIDF : log(TF + 1) * IDF
=> 단어의 빈도를 계산하여, 단어마다 가중치를 부여하겠다는것! (의미는 담기지 않지만, 단어의 중요도는 파악할 수 있다)
단어의 순서는 고려되지 않음! 뿐만 아니라 단어간의 유사도는 여전히 고려되지 않는다
더보기

이런 수식도 있는데,, 사실 이해는 안간다 근데 외워야 할것같긴하고,,,
[word embedding]
워드 임베딩을 추가적으로 진행하여 단어간의 유사도까지 추가해준다!
=> 단어를 벡터로 표현 == 비슷한 단어면, 벡터간의 거리가 가깝도록 만들어준다!
어떻게 비슷한 단어인걸 파악하는가? -> 한 문장에서 동시에 등장하는 비율이 높으면 similar한것이라고 판단하는 등,,
=> Word2vec : 이 과정에서 사용되는게 PGM (Probabilistic Graphical Model)이다!
-> 뒷부분에 나오지만,, word2vec은 inductive bias가 너무!!!! 강해서 오히려 문제가된다
-> 이 문제를 해결한것 (inductive bias를 줄인것)이 contextual word embedding이고, 이게 ELMo, BERT, GPT등등에 사용된다
[PGM] : probabilistic Graphical Model
graph를 이용한 joint distribution이다! -> 그래프가 주어졌을 때, 어떻게 goint distribution으로 표현되는지를 알 수 있어야한다.
Yi의 parent가 주어지면, yi는 predecessor들과 '독립'이다! -> 표현할 때 곱하기로 표현이 가능해진다!)
=> 곱하기로 표현되면, log를 씌워서 시그마(덧셈)으로 정리할 수 있다!
더보기




-> 해보자!
P(A,B,C,D) = ?
= P(A|없음) P(B|A) P(C|A) P(D|A,C)
= P(A) P(B|A) P(C|A) P(D|A,C)
P(X,Y,Z) = ?
(a) = P(X| )P(Y|Z)P(Z|X) = P(X)P(Y|Z)P(Z|X)
(b) = P(X|Z)P(Y| )P(Z|Y)
(c) = P(X|Z)P(Y|Z)P(Z| )
(d) = P(Z| )P(Y| )P(Z|X,Y)
P(D,I,G,S,L) = ?
= P(D| )P(I| )P(G|D,I)P(S|I)P(L|G)
=> 각 노드별 확률이 정해져있으므로 그냥 대입해서 계산하면 된다!
P(Wt-2, Wt-1,Wt, Wt+1, Wt+2) = ?
왼쪽 = P(Wt-2)P(Wt-1)P(Wt|Wt-2,Wt-1,Wt+1,Wt+2)P(Wt+1)P(Wt+2)
오른쪽 = P(Wt=2|Wt)P(Wt-1|Wt)P(Wt)P(Wt+1|Wt)P(Wt+2|Wt)
[Word2Vec]
-> 이것또한 학습되는것! => log likelihood를 높이는 방향으로 진행해준다!

어떤 그래프를 사용하는지에 따라 방식이 달라진다!
CBOW : 지금 단어 기준 앞뒤 n개씩 (그림은 2개씩) 보고 결정하는것이고
skipgram : 지금 단어르 가지고, 앞뒤 n개씩을 결정하는것이다!

-> P(W1:T) 를 구하는건 그래프를 보고 joint 를 해주면 된다! 간단간단!
곱셈으로 표현되므로, 이걸 log에 넣으면 덧셈으로 표현해줄 수 있다!
이 때, exp가 나온이유는,, 정규분포를 따르기 때문이겠지.,.? 암튼 거기로 넣으면 내적으로 표현이 가능해진다.
어떻게 정리하면 vt를 구할 수 있다.. 뭐래닝 수식외우기 넘 힘들고 싫은데,,,

-> 그래프 모양이 달라져서 log씌운 다음 시그마 비뀌는것만 좀 달라졌지 똑같다!
=> 아무튼 joint로 표현해보는게 중요한것같다!
[RNN] : Recurrent NN
여러번 돌려서 sequence를 처리하고, sequence(혹은 vector)를 결과로 내는 모델이다.
t 시점에 모델의 input으로 들어가는게 xt한개가 아니라, yt-1도 같이 들어간다! -> 여기서 또 yt가 나오면
t+1시점에는 xt+1와 yt를 같이 input으로 넣어주는 모델이다!
[markov chain]
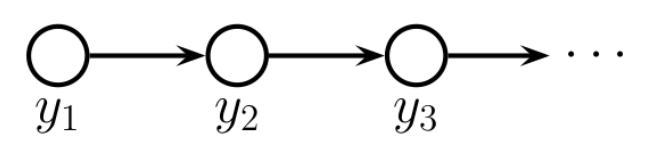
-> PGM으로 그려보면 이런모양이 나온다! y1이 결정되면 y2가 결정,, y2가 결정되면 y3가 결정된다
이런 방법의 특징은??? y1이랑 y3는 독립이 된다!
이런 특징이 너무 강한 inductive bias를 주어 오히려 문제가 된다
[vec2Seq]
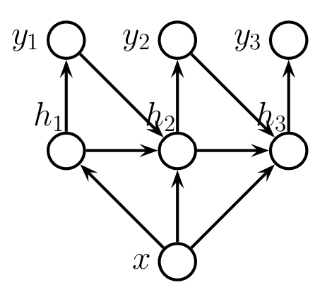
첫번째 시점에서는 x를 넣어서 h1이랑 y1을 얻었다
-> 두번째 시점에서는 h1이랑 y1, x를 넣어서 h2, y2를 뽑아낸다!
-> 이렇게 시간단위로 반복한다
=> 즉 저 모양자체를 PGM으로 보고 joint distribution을 만들 수 있어야한다!
[Seq2Seq]

-> 돌아가는건 위랑 똑같음! 이걸보고 joint distribution으로 표현할 수 있으면 된다.
만약 input seq랑 output seq의 길이가 다르면?

이런 그림이 나오게 된다!
[teacher forcing]
모델이 뽑은 output이 true일 확률을 생각한다
-> 이건 t시점에서의 input에 대해서만 생각하는것이므로, 이전 시점의 input들은 전부 정답라벨을 넣어준다! (모델이 뽑은 output이 아니라)
=> P(w1:t) = PGM그래프를 보고 joint distribution을 해보면 된다! = ㅠ(P(Wt|W1:t-1) 곱셈으로 정리된다!

-> 이걸 log에 넣으면 덧셈으로 정리된다!
[BPTT] : Backpropagation Through Time
-> gradient를 구하는 backpropagation도, PGM으로 그려볼 수 있다!

-> PGM으로 그려볼 수 있다는건, 확률들을 전부 joint distribution으로 표현해줄 수 있다는것
== log를 씌워서 덧셈으로 정리할 수 있다는것!
[GRU, LSTM]
-> 일반적인 RNN의 문제점을 해결하기 위해 제시된 모델들!
문제1 : input이 너무 길어지면 초반에 등장한 단어(즉 과거에 처리된 단어)들을 잘 기억하지 못한다는 문제점
== gradient vanishing문제가 생겼다
residual net과 비슷하게 덧셈해주는 방법으로 해결하려 했다.

전체적으로 PGM을 보고, joint distribution으로 잘 표현하고, 이걸 log likelihood로 잘 표현하는것까지? 가 중요한 부분인것같다!
나머지 수식은 잘 모르겠다.....어렵군,,,

728x90
'학교 > 딥러닝' 카테고리의 다른 글
| 5. Beyond supervised Learning - self supervised learning (2) | 2024.06.13 |
|---|---|
| 4. Beyond supervised learning - 데이터가 적을때 (1) | 2024.06.13 |
| 3. less inductive bias - transformer (2) | 2024.06.13 |
| 1. inductive bias - image (2) | 2024.06.11 |
| 0. MAP (0) | 2024.06.11 |




