고정 헤더 영역
상세 컨텐츠
본문
728x90

쿼리 최적화에 대해 배운다.
- System R (Selinger)
- Cascades
두가지 옵티마이저를 주로 사용한다고 한다. 강의에서 배울건 System R 옵티마이저라고 한다.

SQL문이 들어오면
- Query Parser가 abstract syntax tree로 만들어줌
- 쿼리가 올바른지, 사용자가 테이블 접근권한지 있는지 확인
- Query rewriter가 쿼리를 표준형식으로 변환 (AST를 변경하는것) -> 옵티마이저에게 전달함-> 뷰를 가져와서, 조인으로 변환하거나, 서브쿼리를 더 적은 쿼리블록으로 변환함
- view를 가져와 쿼리에 통합해준다
- 받은 변환된 AST를 가지고 효율적인 계획 (plan)으로 변환함비용추정을 할 때 데이터베이스 카탈로그를 통해 다양한 통계값들을 받아오는것
- 계획생성, 비용추정을 한다 (비용이 저렴한걸 선택!)
- 옵티마이저가 최적의 plan을 하나 선택해서 Query Executor (실행기)로 전달해준다.
옵티마이저가 최적화를 할때는 쿼리블록 단위로 처리한다 (select, projection, join, select 등을 포함하는 단위)
-> 즉 전에 sql을 최적화 하는게 아니라, 쿼리 블록단위로 최적화를 진행함
-> 서브쿼리 또한 독립적으로 최적화된다.
그러면 최적화 과정은 어떻게 될까?
- 쿼리블록을 트리형태의 관계대수 집합표현으로 변환함
- 각각의 연산자는 적절한 알고리즘으로 구현됨
- 트리를 만들 때, 다양한 순서로 적용할 수 있다 (재배열 가능)
Query Optimization의 구성요소
3가지 구성요소는 각각 독립되어 있다.
== 따로따로 수정해도 서로 영향이 없음
- plan space : 퀴리를 구현할 수 있는 다양한 방법을 나열하고, 하나를 선택
- cost estimation : cost계산 (가장 빠른것 == 적은것을 선택)
- search strategy : plan space에 나열된 각각의 계획들중에, 가장 저렴한 비용을 가지는 계획을 찾는 효율적인 방법
관계대수
쿼리 plan에서는, 연산의 순서를 바꾸어서 다양한 계획을 만들어낸다.
각 관계대수의 연산순서가 바뀌었을 때 결과가 동일하게 유지되는지 알아본다.
SELECT
- cascade : 여러개의 조건을 한번에 선택하는것과, 하나씩 계단식으로 선택하는건 결과가 같음

- commute : 교환법칙! 조건1 다음 조건2랑 조건2다음 조건1이랑 같음

PROJECTION
- cascade : 최종적으로 뽑는 마지막 컬럼만 유지하면 결과는 같음 == 중간에 다른 컬럼을 잠깐 선택해도 괜찮음

Cartesian Product
- associative : 결합법칙, 3개의 곱셈중 어느걸 먼저해도 상관없음

- commutative : 교환법칙. 곱셈 순서를 변경해도 상관없음

Join
데카르트곱에 조건을 추가하면 join이 된다.
하지만 join에 결합법칙, 교환법칙이 성립하지는 않는다.

-> 이렇게 조건때문에, 바꾸었을 때 성립하지 않는 join이 되거나, 결과가 달라질 수 있다.
맨 마지막을 보면, join 대신에 데카르트 곱을 포함시켜서 완성했다.
Heuristics
항상 정답은 아니지만, 대부분 이렇다고 한다!
Selection
join보다 selection이 항상 더 저렴하다는 heuristics을 가져온다.
즉.. 조인한 다음에 select하는 query가 있으면, 반대로 select한 다음에 join을 하도록 수정해준다.
(나중에 어짜피 안 쓸 튜플을 위해 join을 사용하지 않겠다는 의지)
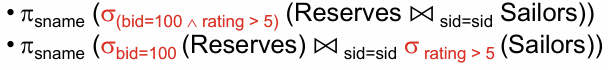
projection
이 또한, join이 있으면 최대한 뒤로 미룬다는 생각이다!!
-> 나중에 몇개의 column만 보여줄거니까, projection먼저 해서 사이즈를 줄인다음에 join을 하겠다는것

Cartesian products
데카르트곱은 최대한 피한다
-> cross-produec보다 세타join을 선택한다.
물리적 동등성
구현상에서 얼마나 동등한지? 를 말하고 있는것같다
즉 원하는 결과에 따라 다양한 구현방법중에 적절한걸 사용하라는듯!
table access
single-tableselection이라고 하면....
- heap scan
- index scan
equi join
- block (chunk) nested loop : 간단한 구현, 메모리활용 굿
- index nested loop : 테이블 하나가 작고, 테이블 하나가 index 되어있을 때 유용
- sort-merge join : 메모리가 작을 때 좋음, 두 테이블의 사이즈가 같으면 굿
- grace hash join : 테이블 크기가 다를 때 좋음 (하나의 테이블이 더 작으면 시도)
- hybrid hash join을 사용할수도 있음
theta join
- block (chunk) nesed loop : 이것밖에 선택지가 없음
728x90
'학교 > 데이터베이스시스템응용' 카테고리의 다른 글
| 28. 15장 : A TYPICAL RELATIONAL QUERY OPTIMIZER (3) (1) | 2024.12.19 |
|---|---|
| 27. 15장 : A TYPICAL RELATIONAL QUERY OPTIMIZER (2) (0) | 2024.12.19 |
| 24. 14장 : EVALUATING RELATIONAL OPERATORS (2) - Sort Merge Join (0) | 2024.12.19 |
| 23. 14장 : EVALUATING RELATIONAL OPERATORS (1) - Nested Loops Join (0) | 2024.12.19 |
| 22. 13장 : EXTERNAL SORTING (5) - 병렬처리 (0) | 2024.12.19 |




